Brand
用手机扫我
在手机上打开
| 是什么 ? | : | a non-interactive commandline tool that easily be called from scripts, cron jobs, terminals without X-Windows support, etc for retrieving files using HTTP, HTTPS, FTP and FTPS the most widely-used Internet protocols. |
| 开发语言 | : | C |
| 开发组织 | : | GNU |
| 官方主页 | : | https://www.gnu.org/software/wget |
| 操作系统 | 包管理器 | 安装命令 |
|---|---|---|
| Windows | scoop | scoop install wget |
| Windows | Chocolatey | choco install -y wget |
| macOS | HomeBrew | brew install wget |
| GNU/Linux | HomeBrew | brew install wget |
| apt | sudo apt-get install -y wget | |
| CentOS | yum | sudo yum install -y wget |
| dnf | sudo dnf install -y wget | |
| openSUSE | zypper | sudo zypper install -y wget |
| Alpine Linux | apk | sudo apk add wget |
| pacman | sudo pacman -Syyu --noconfirm | |
| Gentoo Linux | Portage | sudo emerge wget |
wget命令的使用格式:
wget [option]... [URL]...查看wget命令的使用帮助。
查看wget的版本信息。
输出更多的信息。
安静模式,不输出信息。
设置下载后的文件路径。
wget -r -p -np -k -E --restrict-file-names=nocontrol -e robots=off http://www.baidu.com-r表示递归下载,会下载所有的链接,不过要注意的是,不要单独使用这个参数,因为如果你要下载的网站也有别的网站的链接,wget也会把别的网站的东西下载下来,所以要加上-np这个参数,表示不下载别的站点的链接。
-np表示不下载别的站点的链接。
-k表示将下载的网页里的链接修改为本地链接
-p表示获得所有显示网页所需的元素,比如图片什么的。
-E或--html-extension表示将保存的URL的文件后缀名设定为.html。
--restrict-file-names=nocontrol表示按照文件名原来的样子,如果URL中有中文必须设置此参数, 否则下载下来的文件是经过URL编码的,有中文的话就会乱码。
-e robots=off表示不理会robots协议。默认的,wget会遵守robots协议, 即如果网站根目录下的robots.txt里有如下配置的话:
User-agent: *
Disallow: /wget是做不了镜像或者下载目录的,使用-e robots=off参数即可绕过该限制。
爬虫会把网站下载到www.baidu.com文件夹中,
在浏览器中打开:
firefox index.html效果如下:
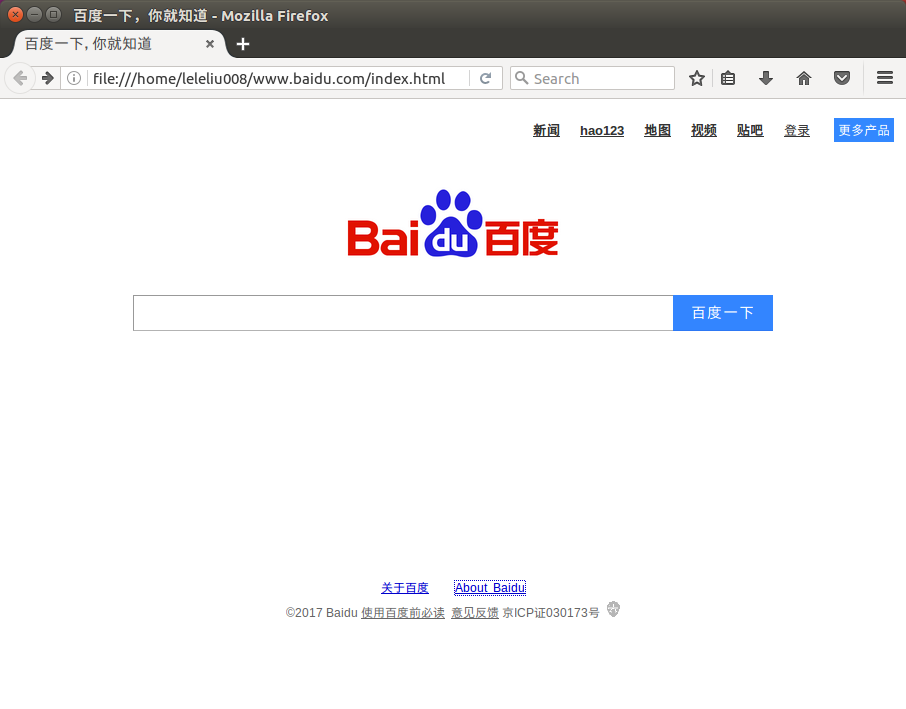
wget提供这个功能是为了镜像网站使用的,所以不要做坏事奥!!