Brand
用手机扫我
在手机上打开
| 是什么 ? | : | a web spider library. |
| 开发语言 | : | Node.js |
| 源码仓库 | : | https://github.com/bda-research/node-crawler |
| 包管理器 | 安装命令 |
|---|---|
| npm | npm install crawler --save |
| yarn | yarn add crawler |
var Crawler = require("crawler");var crawler = new Crawler(optionObject);Crawler构造函数接收一个参数对象,下面是这个对象的字段:
最大并发数量。类型是Number。
因为一个任务队列中可以有很多个任务,但是,同时能够执行的任务不能超过maxConnections个, 其他任务必须等待前面的任务。
任务队列中两个任务执行的时间间隔,单位是ms。类型是Number。
每个任务执行的时候的回掉函数。任务执行的实质是发起一个HTTP的GET请求。 该函数的签名如下:
function(err, result, done)任务队列,该队列中只有一个任务,且给的是一个要抓取的地址,没有其他参数设置。
示例:
crawler.queue('http://www.amazon.com');任务队列,该队列中只有一个任务,且给的是一个参数对象。
options中的字段如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| uri | String | 要抓取的网页地址 |
| limiter | String | 限速器名称 |
| proxy | String | HTTP代理 |
| html | String | 要抓取的是一段HTML,比如你本地的一些HTML文件,通过流读取进来,抓取里面份内容 |
| callback | Function | 请求回来的回掉,如果这里设置了,那么Crawler构造函数里面设置的全局的回掉就不执行了 |
| jQuery | Boolean | String | Object | 因为,我们抓取的主要是HTML文档,实际上就是操作DOM,在前端开发中,没有MVC或者MVVM框架出现之前, 曾经很长一段时间主要使用jQuery进行操作DOM的,他使用起来非常简单(只要你对CSS选择器非常熟悉的话)。 现在,我们抓取HTML网页中的内容也是操作DOM,所以,把jQuery哪种操作DOM的方法带入进来,降低我们的学习成本。 默认是 jQuery: true,当启用jQuery之后,我们就可以使用熟悉的jQuery中的$了。如果类型是String,表示使用的是哪种支持jQuery方法操作DOM的库,默认是 cheerio。如果类型是Object。 |
示例:
crawler.queue({
uri:"http://www.google.com",
limiter:"key1",// for connection of 'key1'
proxy:"http://user:pass@127.0.0.1:8080"
});
任务队列,该队列中可以有多个任务,这多个任务使用数组传入。
示例:
crawler.queue(['http://www.google.com/','http://www.yahoo.com']);
任务队列,该队列中可以有多个任务,这多个任务使用数组传入。
示例:
crawler.queue([{
uri: 'http://parishackers.org/',
jQuery: false,
// The global callback won't be called
callback: function (error, res, done) {
if(error){
console.log(error);
}else{
console.log('Grabbed', res.body.length, 'bytes');
}
done();
}
}]);
获取队列的长度。
事件处理。
当任务被加入调度器时候触发。
示例:
crawler.on('schedule', function(options) {
options.proxy = "http://proxy:port";
});
当发起HTTP请求的时候触发。
示例:
crawler.on('request', function(options) {
options.qs.timestamp = new Date().getTime();
});
当任务队列为空时候触发。
示例:
crawler.on('drain', function() {
// For example, release a connection to database.
db.end(); // close connection to MySQL
});
彼岸桌面这个网站上有大量的精美桌面图片, 我比较喜欢汽车频道里面的汽车图片,我想要把这些汽车图片下载下来。
汽车频道的首页的网址是:http://www.netbian.com/qiche, 从第二页开始,网址是:http://www.netbian.com/qiche/index_N.htm,N的范围是[2, 19]。
网页中的图片列表数据是通过XHR获取到的,所以通过查看他的源码是看不出网页结构的。 我们需要使用Firefox或者Chrome浏览器查看网页的结构。
在页面上右键菜单中选择"Inspect Element"调出浏览器的调试工具。可以使用最左边的箭头形状的工具, 点击一张图片,这时候能够在下面显示对应的源代码,如下:
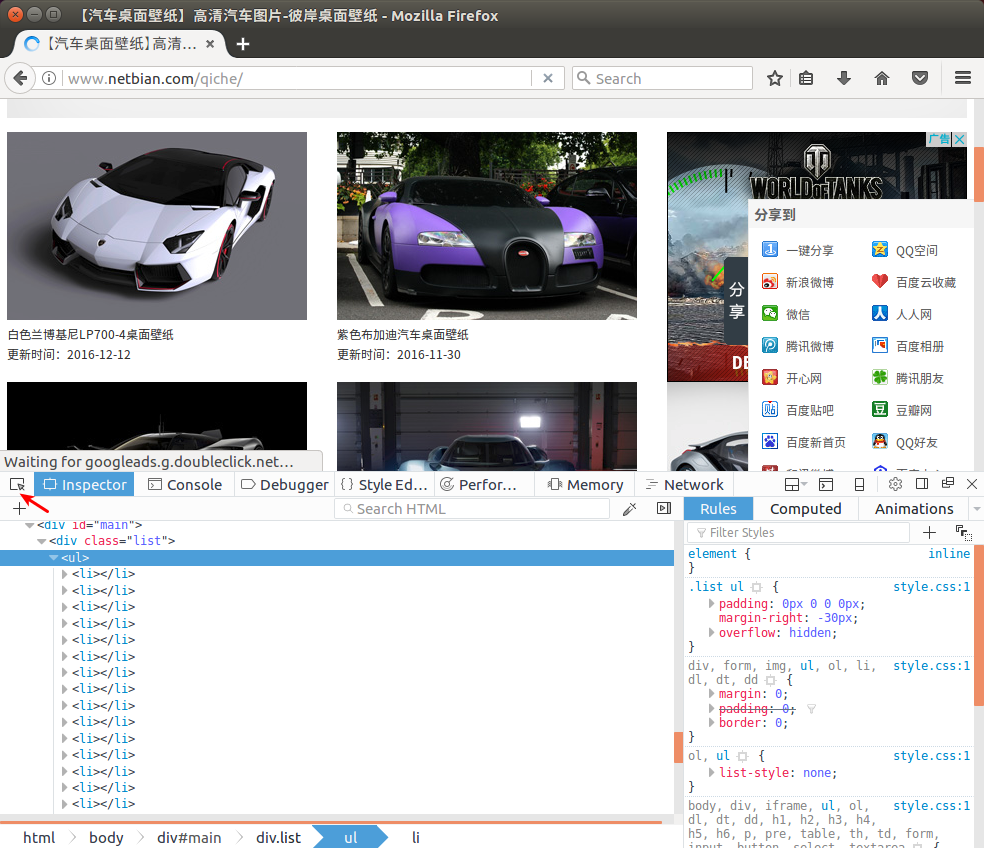
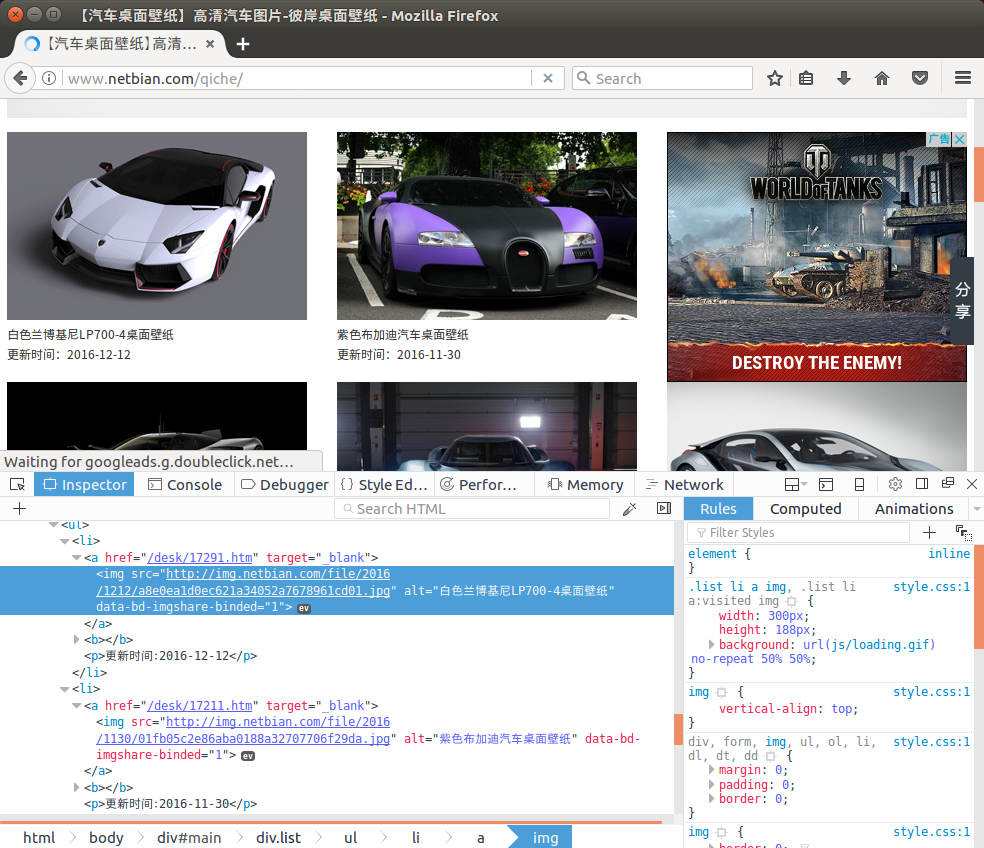
我们已经找到了规律:
ul+li实现的,通常都是使用这两个HTML标签实现的。ul>li*N>a>img来表达。data/目录下。data/目录下创建以YYYYMMddHHmmss为格式的文件夹。data/{YYYYMMddHHmmss}/images.txt文件中。 我们先只是获取到这些img标签中的src和alt属性的值。 文件的每一行一条记录,先src,后alt,用一个空格隔开。data/{YYYYMMddHHmmss}/images目录下。最终的数据目录文件目录结构如下:
data
├── 20161130120022
│ ├── images.txt
│ └── images
│ ├── 1-AeroGT概念车桌面壁纸.jpg
│ ├── 3-紫色布加迪汽车桌面壁纸.jpg
│ ├── 3-白色兰博基尼LP700-4桌面壁纸.jpg
│ └── ...
└── 20161130120122
├── images.txt
└── images
├── 1-AeroGT概念车桌面壁纸.jpg
├── 2-紫色布加迪汽车桌面壁纸.jpg
├── 3-白色兰博基尼LP700-4桌面壁纸.jpg
└── ...
step1、使用npm命令创建一个node.js工程
mkdir node-crawler-img && cd node-crawler-img && npm init -ystep2、安装node-crawler
npm install --save crawlerstep3、安装moment.js
npm install --save momentstep4、创建app.js文件,内容如下
var fs = require('fs');
var moment = require('moment');
var Crawler = require('crawler');
var dataDir = "data/";
var thisTimeDir = dataDir + moment().format("YYYYMMDDHHmmss");
var imagesDir = thisTimeDir + "/images";
var imagesFile = thisTimeDir + "/images.txt";
var uris = new Array();
function prepareDirs() {
if (!fs.existsSync(dataDir)) {
fs.mkdirSync(dataDir);
}
fs.mkdirSync(thisTimeDir);
fs.mkdirSync(imagesDir);
}
function prepareURIs() {
uris.push("http://www.netbian.com/qiche");
for(var i = 2; i < 2; i++) {
uris.push("http://www.netbian.com/qiche/index_" + i + ".htm");
}
}
function appendFile(src, alt) {
fs.appendFileSync(imagesFile, src + " " + alt + "\n");
}
function callback(err, response, done) {
if(err) {
console.log(err);
} else {
var $ = response.$;
$('li').each(function(index, li) {
var a = $(li).children('a');
var img = a.children('img');
var src = img.attr('src');
var alt = img.attr('alt');
if (src && alt) {
appendFile(src, alt);
}
});
}
done();
}
function downloadPic() {
//node-crawler模块已经依赖了request模块
var request = require('request');
fs.readFile(imagesFile, function(err, dataBuffer) {
var allText = dataBuffer.toString();
var lineTextArray = allText.split('\n');
lineTextArray.forEach(function(lineText, index, lineTextArray) {
var fieldArray = lineText.split(' ');
console.log(fieldArray);
var uri = fieldArray[0];
if(uri) {
request(uri)
.on('error', function(err) {
console.log(err);
})
.pipe(fs.createWriteStream(imagesDir + "/" + index + ".jpg"));
}
});
});
}
function grabInfo() {
var crawler = new Crawler({
maxConnections: 10,
callback: callback
});
crawler.queue(uris);
crawler.on('drain', function() {
console.log('grab info finished!');
downloadPic();
});
}
function main() {
prepareDirs();
prepareURIs();
grabInfo();
}
main();
step5、运行app.js
node app.js